Interaction Plot in R Continuous Variables
Splitting up continuous variables is generally a bad idea. In terms of statistical efficiency, the popular practice of dichotomising continuous variables at their median is comparable to throwing out a third of the dataset. Moreover, statistical models based on split-up continuous variables are prone to misinterpretation: threshold effects are easily read into the results when, in fact, none exist. Splitting up, or 'binning', continuous variables, then, is something to avoid. But what if you're interested in how the effect of one continuous predictor varies according to the value of another continuous predictor? In other words, what if you're interested in the interaction between two continuous predictors? Binning one of the predictors seems appealing since it makes the model easier to interpret. However, as I'll show in this blog post, it's fairly straightforward to fit and interpret interactions between continuous predictors.
Data
To keep things easy, I will use a simulated dataset with two continuous predictors (pred1 and pred2) and one continuous outcome. The dataset is available here.
df <- read.csv ( "http://homeweb.unifr.ch/VanhoveJ/Pub/Data/example_interaction.csv" ) Exploratory plots
First, let's draw some quick graphs to get a sense of how the predictors and the outcome are related.
# 3 plots next to each other par ( mfrow = c ( 1 , 3 )) # Intercorrelation pred1/pred2 plot ( pred2 ~ pred1 , df ) lines ( lowess ( df $ pred1 , df $ pred2 ), col = "red" ) # Pred1 vs. outcome plot ( outcome ~ pred1 , df ) lines ( lowess ( df $ pred1 , df $ outcome ), col = "red" ) # Pred2 vs. outcome plot ( outcome ~ pred2 , df ) lines ( lowess ( df $ pred2 , df $ outcome ), col = "red" ) 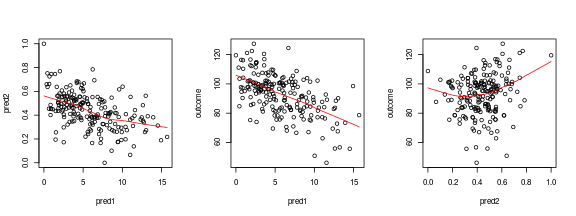
# Normal plotting again par ( mfrow = c ( 1 , 1 )) Left: The predictors are negatively correlated with each other. Middle:
pred1is negatively correlated with the outcome. Right:pred2seems to be nonlinearly correlated with the outcome..
When we suspect there's an interaction between two predictors, it's useful to draw conditioning plots as well. For these plots, the dataset is split up into a number of overlapping equal-sized regions defined by a conditioning variable, and the relationship between the predictor of interest and the outcome within each region is plotted.
# coplot's in the lattice package library ( lattice ) coplot ( outcome ~ pred1 | pred2 , data = df , number = 4 , rows = 1 , panel = panel.smooth ) 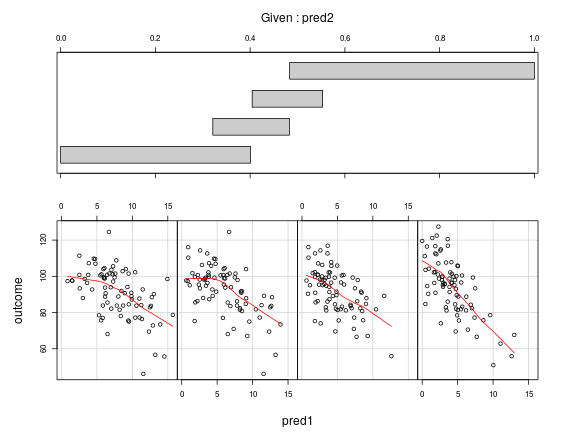
coplot ( outcome ~ pred2 | pred1 , data = df , number = 4 , rows = 1 , panel = panel.smooth ) 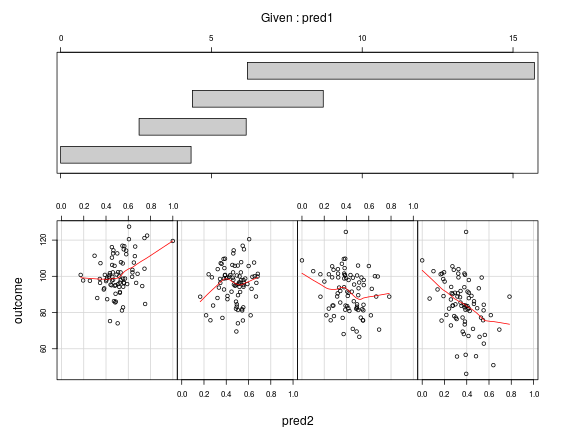
Top: The effect of
pred1on the outcome in four regions defined by pred2. The negative relationship grows stronger aspred2increases (from left to right). Bottom: The effect ofpred2on the outcome in four regions defined by pred1. The relationship may be positive for small values ofpred1, but becomes negative for larger values (from left to right).
Fitting the model
I find it easiest to fit the interaction between two continuous variables as a wiggly regression surface. A wiggly regression surface is the generalisation of a wiggly curve, such as the one in Figure 3 in this earlier blog post, into two dimensions. The advantage of fitting a wiggly surface rather than a plane is that we don't have to assume that the interaction is linear. Rather, the shape of the surface will be estimated from the data. To fit such wiggly surfaces, we need the gam() function in the mgcv package. The wiggly regression surface is fitted by feeding the two predictors to a te() function within the gam() call.
# install.packages("mgcv") library ( mgcv ) m1 <- gam ( outcome ~ te ( pred1 , pred2 ), data = df ) A numerical summary of the model can be obtained using summary(), but as you can see, this doesn't offer much in the way of interpretable results.
summary ( m1 ) ## ## Family: gaussian ## Link function: identity ## ## Formula: ## outcome ~ te(pred1, pred2) ## ## Parametric coefficients: ## Estimate Std. Error t value ## (Intercept) 92.769 0.751 124 ## ## Approximate significance of smooth terms: ## edf Ref.df F ## te(pred1,pred2) 4.63 5.41 28 ## ## R-sq.(adj) = 0.427 Deviance explained = 44.1% ## GCV = 115.92 Scale est. = 112.65 n = 200 To understand what the wiggly regression surface looks like, you need to plot it. This can be done using the vis.gam() function. The two plots below show the same regression surface: once as a three-dimensional plot and once as a contour plot. The latter can be read like a topographic map of hilly terrain: the contour lines connect points on the surface with the same height, and the closer the contour lines are to each other, the steeper the surface is.
# 3-d graph vis.gam ( m1 , plot.type = "persp" , color = "terrain" , theta = 135 , # changes the perspective main = "" ) 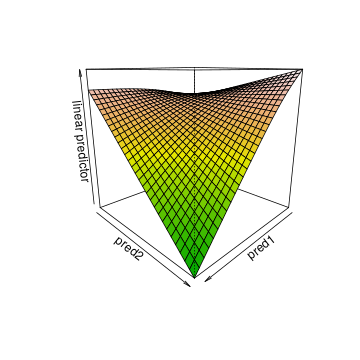
# A contour plot vis.gam ( m1 , plot.type = "contour" , color = "terrain" , main = "" ) 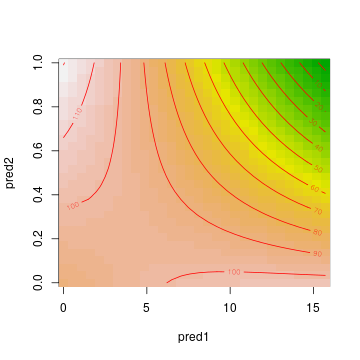
What can be gleaned from these plots? First of all, the outcome variable is largest for low pred1 and pred2 values. Second, pred1 and pred2 both have strong negative effects when the respective other variable is large, but their effect is quite weak when the other variable is low.
The contour lines are useful to quantify this. Going along the y-axis for a low pred1 value (say, 2.5), we only cross one contour line, and we seem to climb slightly. Going along the y-axis for a large pred1 value (say, 12.5), we cross 8 contour lines and we descend considerably, from around 100 on the outcome variable to below 30. Similarly, going along the x-axis for a low pred2 value (say, 0.2), we descend slightly (perhaps 20 units). Going alongside the x-axis for a large pred2 value (say, 0.8), we cross 10 contour lines. The effect of pred1, then, depends on the value of pred2 and vice versa. Or in other words, pred1 and pred2 interact with each other.
Improved visualisation
I find it useful to plot a contour plot with the wiggly regression surface with the interaction alongside a contour plot with a regression surface without an interaction. I find this helps me to better understand what the interaction consists of. This is particularly helpful when the one or two of the predictors are nonlinearly related to the outcome. To draw the second contour plot, first fit a model without an interaction. By feeding each predictor to a separate te() function, potentially nonlinear regression curves are estimated for both predictors.
m2 <- gam ( outcome ~ te ( pred1 ) + te ( pred2 ), data = df ) Then plot both contour plots alongside each other. Here I also set the too.far parameter. This way, region of the graph for which no combinations of predictor variables are available are not plotted.
# Two plots next to each other par ( mfrow = c ( 1 , 2 )) vis.gam ( m2 , plot.type = "contour" , color = "terrain" , too.far = 0.1 , main = "without interaction" ) vis.gam ( m1 , plot.type = "contour" , color = "terrain" , too.far = 0.1 , main = "with interaction" ) 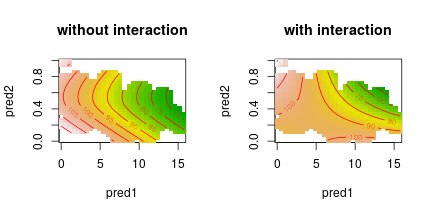
par ( mfrow = c ( 1 , 1 )) Decomposing a regression surface into main effects and an interaction
It may be useful to 'decompose' the regression surface into the main effects associated with each predictor and the interaction itself. This can be done by fitting the main effects and the interaction in separate ti() (not te()) functions. This fits non-linear main effects, which is what we want: this way, the interaction term doesn't absorb any nonlinearities not modelled by the linear main effects.
m3 <- gam ( outcome ~ ti ( pred1 ) + ti ( pred2 ) + # main effects ti ( pred1 , pred2 ), # interaction data = df ) summary ( m3 ) ## ## Family: gaussian ## Link function: identity ## ## Formula: ## outcome ~ ti(pred1) + ti(pred2) + ti(pred1, pred2) ## ## Parametric coefficients: ## Estimate Std. Error t value ## (Intercept) 90.37 0.86 105 ## ## Approximate significance of smooth terms: ## edf Ref.df F ## ti(pred1) 1.68 2.06 51.44 ## ti(pred2) 1.00 1.00 6.82 ## ti(pred1,pred2) 5.71 7.26 5.11 ## ## R-sq.(adj) = 0.44 Deviance explained = 46.4% ## GCV = 115.6 Scale est. = 110.17 n = 200 The wiggly regression surface of m1 has here been decomposed into the main effects of pred1 and pred2 and an interaction between them. Both main effects and the interaction are significant.
The edf values in the table above, incidentally, express how nonlinear the effects are estimated to be. Values close to 1 indicate that the effect is linear, whereas a value of 2 suggests that the effect can be modelled using a linear and a quadratic term etc. Here both main effects could sensibly be modelled linearly, but the interaction couldn't. (A linear interaction means that you multiply both predictors together and use this product as an additional predictor.)
There's much more to fitting nonlinearities and interactions using gam() than discussed here, but hopefully this was useful enough to dissuade you from carving up continuous variables when you're interested in their interaction.
Source: https://janhove.github.io/analysis/2017/06/26/continuous-interactions